Data - AP Statistics
Card 1 of 552
Obtain a normal distribution table or calculator for this problem.
Approximate the  -percentile on the standard normal distribution.
-percentile on the standard normal distribution.
Obtain a normal distribution table or calculator for this problem.
Approximate the
Tap to reveal answer
The  -percentile is the value such that
-percentile is the value such that  percent of values are less than it.
percent of values are less than it.
Using a normal table or calculator (such as R, using the command qnorm(0.9)), we get that the approximate  -percentile is about
-percentile is about  .
.
The
Using a normal table or calculator (such as R, using the command qnorm(0.9)), we get that the approximate
← Didn't Know|Knew It →
Find the first and third quartile for the set of data

Find the first and third quartile for the set of data
Tap to reveal answer
In order to find the first and third quartiles, we haave to find the 25th and 75th percentiles, respectively.
To find the 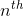 percentile, we find the product of
percentile, we find the product of  and the number of items
and the number of items  in the set.
in the set.

We then round that number  up if it is not a whole number, and the
up if it is not a whole number, and the 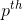 term in the set is the
term in the set is the  percentile.
percentile.
For this problem, to find the  and
and  percentile, we first find that there are 14 items in the set. We find their respective products to be
percentile, we first find that there are 14 items in the set. We find their respective products to be
 and
and

As such, the  and
and  percentiles are the fourth and eleventh terms in the set, or
percentiles are the fourth and eleventh terms in the set, or

In order to find the first and third quartiles, we haave to find the 25th and 75th percentiles, respectively.
To find the
We then round that number
For this problem, to find the
As such, the
← Didn't Know|Knew It →
Use the following five number summary to determine if there are any outliers in the data set:
Minimum: 
Q1: 
Median: 
Q3: 
Maximum: 
Use the following five number summary to determine if there are any outliers in the data set:
Minimum:
Q1:
Median:
Q3:
Maximum:
Tap to reveal answer
An observation is an outlier if it falls more than ") above the upper quartile or more than
above the upper quartile or more than ") below the lower quartile.
below the lower quartile.

= 11..5(6)= 9")
 . The minimum value is
. The minimum value is  so there are no outliers in the low end of the distribution.
so there are no outliers in the low end of the distribution.
 . The maximum value is
. The maximum value is  so there are no outliers in the high end of the distribution.
so there are no outliers in the high end of the distribution.
An observation is an outlier if it falls more than
← Didn't Know|Knew It →
For a data set, the first quartile is  , the third quartile is
, the third quartile is  and the median is
and the median is  .
.
Based on this information, a new observation can be considered an outlier if it is greater than what?
For a data set, the first quartile is
Based on this information, a new observation can be considered an outlier if it is greater than what?
Tap to reveal answer
Use the  criteria:
criteria:
This states that anything less than  or greater than
or greater than  will be an outlier.
will be an outlier.
Thus, we want to find
 where
where  .
.
 =1.5\cdot 30=45")
 = 70 + 45 = 115")
Therefore, any new observation greater than 115 can be considered an outlier.
Use the
This states that anything less than
Thus, we want to find
Therefore, any new observation greater than 115 can be considered an outlier.
← Didn't Know|Knew It →

Which values in the above data set are outliers?
Which values in the above data set are outliers?
Tap to reveal answer
Step 1: Recall the definition of an outlier as any value in a data set that is greater than  or less than
or less than  .
.
Step 2: Calculate the IQR, which is the third quartile minus the first quartile, or  . To find
. To find  and
and  , first write the data in ascending order.
, first write the data in ascending order.
 . Then, find the median, which is
. Then, find the median, which is  . Next, Find the median of data below
. Next, Find the median of data below  , which is
, which is  . Do the same for the data above
. Do the same for the data above  to get
to get  . By finding the medians of the lower and upper halves of the data, you are able to find the value,
. By finding the medians of the lower and upper halves of the data, you are able to find the value,  that is greater than 25% of the data and
that is greater than 25% of the data and  , the value greater than 75% of the data.
, the value greater than 75% of the data.
Step 3:  . No values less than 64.
. No values less than 64.
 . In the data set, 105 > 104, so it is an outlier.
. In the data set, 105 > 104, so it is an outlier.
Step 1: Recall the definition of an outlier as any value in a data set that is greater than
Step 2: Calculate the IQR, which is the third quartile minus the first quartile, or
Step 3:
← Didn't Know|Knew It →
You are given the following information regarding a particular data set:
Q1: 
Q3: 
Assume that the numbers  and
and  are in the data set. How many of these numbers are outliers?
are in the data set. How many of these numbers are outliers?
You are given the following information regarding a particular data set:
Q1:
Q3:
Assume that the numbers
Tap to reveal answer
In order to find the outliers, we can use the  and
and  formulas.
formulas.




Only two numbers are outside of the calculated range and therefore are outliers:  and
and  .
.
In order to find the outliers, we can use the
Only two numbers are outside of the calculated range and therefore are outliers:
← Didn't Know|Knew It →
Use the following five number summary to answer the question below:
Min: 
Q1: 
Med: 
Q3: 
Max: 
Which of the following is true regarding outliers?
Use the following five number summary to answer the question below:
Min:
Q1:
Med:
Q3:
Max:
Which of the following is true regarding outliers?
Tap to reveal answer
Using the  and
and  formulas, we can determine that both the minimum and maximum values of the data set are outliers.
formulas, we can determine that both the minimum and maximum values of the data set are outliers.


This allows us to determine that there is at least one outlier in the upper side of the data set and at least one outlier in the lower side of the data set. Without any more information, we are not able to determine the exact number of outliers in the entire data set.
Using the
This allows us to determine that there is at least one outlier in the upper side of the data set and at least one outlier in the lower side of the data set. Without any more information, we are not able to determine the exact number of outliers in the entire data set.
← Didn't Know|Knew It →
A certain distribution has a 1st quartile of 8 and a 3rd quartile of 16. Which of the following data points would be considered an outlier?
A certain distribution has a 1st quartile of 8 and a 3rd quartile of 16. Which of the following data points would be considered an outlier?
Tap to reveal answer
An outlier is any data point that falls  above the 3rd quartile and below the first quartile. The inter-quartile range is
above the 3rd quartile and below the first quartile. The inter-quartile range is  and
and  . The lower bound would be
. The lower bound would be  and the upper bound would be
and the upper bound would be  . The only possible answer outside of this range is
. The only possible answer outside of this range is  .
.
An outlier is any data point that falls
← Didn't Know|Knew It →
Obtain a normal distribution table or calculator for this problem.
Approximate the -percentile on the standard normal distribution.
Obtain a normal distribution table or calculator for this problem.
Approximate the
Tap to reveal answer
The -percentile is the value such that percent of values are less than it.
Using a normal table or calculator (such as R, using the command qnorm(0.9)), we get that the approximate -percentile is about .
The
Using a normal table or calculator (such as R, using the command qnorm(0.9)), we get that the approximate
← Didn't Know|Knew It →
Find the first and third quartile for the set of data
Find the first and third quartile for the set of data
Tap to reveal answer
In order to find the first and third quartiles, we haave to find the 25th and 75th percentiles, respectively.
To find the percentile, we find the product of and the number of items in the set.
We then round that number up if it is not a whole number, and the term in the set is the percentile.
For this problem, to find the and percentile, we first find that there are 14 items in the set. We find their respective products to be
and
As such, the and percentiles are the fourth and eleventh terms in the set, or
In order to find the first and third quartiles, we haave to find the 25th and 75th percentiles, respectively.
To find the
We then round that number
For this problem, to find the
As such, the
← Didn't Know|Knew It →
A study is trying to determine if a particular medication (Y) is effective in weight loss. Patients participating in the study were randomly assigned to groups A, B, C, D, or E. Group A will receive one dose of Y, Group B will receive two doses of Y, Group C will receive three doses of Y, Group D will receive four doses of Y, and Group E will serve as the control group.
Which group will be receiving the placebo (a sugar pill)?
A study is trying to determine if a particular medication (Y) is effective in weight loss. Patients participating in the study were randomly assigned to groups A, B, C, D, or E. Group A will receive one dose of Y, Group B will receive two doses of Y, Group C will receive three doses of Y, Group D will receive four doses of Y, and Group E will serve as the control group.
Which group will be receiving the placebo (a sugar pill)?
Tap to reveal answer
The control group in an experiment typically receives placebo treatments (in this case - Group E). Since all of the other groups are receiving at least one dose of the medication, they are considered to be experimental groups.
The control group in an experiment typically receives placebo treatments (in this case - Group E). Since all of the other groups are receiving at least one dose of the medication, they are considered to be experimental groups.
← Didn't Know|Knew It →
To test if vitamin C actually makes people feel better, a vitamin company decides to run a 5-day study where they give one group of 100 sick participants vitamin C pills and another group of 100 sick people placebo pills, and monitored another group of 100 sick people who took no pills.
At the end of the 5-day experiment, 90 participants in the vitamin C group reported feeling better. 30 participants in the no-pill group felt better after the 5-day period. Interestingly, 50 participants in the placebo group felt better after the 5-day period.
What could explain these numbers?
To test if vitamin C actually makes people feel better, a vitamin company decides to run a 5-day study where they give one group of 100 sick participants vitamin C pills and another group of 100 sick people placebo pills, and monitored another group of 100 sick people who took no pills.
At the end of the 5-day experiment, 90 participants in the vitamin C group reported feeling better. 30 participants in the no-pill group felt better after the 5-day period. Interestingly, 50 participants in the placebo group felt better after the 5-day period.
What could explain these numbers?
Tap to reveal answer
The placebo effect is when effects are seen in a group of people who did not actually receive a treatment.
In the vitamin C group, 90 participants felt better.
Naturally (no-pill), 30 participants felt better.
With the placebo, 50 participants felt better. Since more people felt better with the placebo than with no treatment at all, it appears that some percentage of people believed that they would feel better with a pill and actually began to feel better due to the placebo effect.
The placebo effect is when effects are seen in a group of people who did not actually receive a treatment.
In the vitamin C group, 90 participants felt better.
Naturally (no-pill), 30 participants felt better.
With the placebo, 50 participants felt better. Since more people felt better with the placebo than with no treatment at all, it appears that some percentage of people believed that they would feel better with a pill and actually began to feel better due to the placebo effect.
← Didn't Know|Knew It →
On a residual plot, the  -axis displays the and the
-axis displays the and the  -axis displays .
-axis displays .
On a residual plot, the
Tap to reveal answer
A residual plot shows the difference between the actual and expected value, or residual. This goes on the y-axis. The plot shows these residuals in relation to the independent variable.
A residual plot shows the difference between the actual and expected value, or residual. This goes on the y-axis. The plot shows these residuals in relation to the independent variable.
← Didn't Know|Knew It →
Let us suppose a company wants to evaluate whether a new medical device works better than current devices. It conducts a small experiment to assess the effectiveness of the new device. To conduct the experiment, the company randomly assigns one group to the new medical device, which requires users to stay well hydrated, and the other group to the old device.
How should we control for confounding variables?
Let us suppose a company wants to evaluate whether a new medical device works better than current devices. It conducts a small experiment to assess the effectiveness of the new device. To conduct the experiment, the company randomly assigns one group to the new medical device, which requires users to stay well hydrated, and the other group to the old device.
How should we control for confounding variables?
Tap to reveal answer
When comparing the effectiveness of a treatment, one should try to ensure that only the treatment varies across groups. In this case, the new device is compared to an old device. However, the new device also requires that users stay well hydrated. If we observe any positive effects from the new device, we won't know whether the new device is effective, or if merely staying well hydrated is actually what is effective. To rule out this confounding variable, we should also ask the group using the old machine condition to stay hydrated as well.
When comparing the effectiveness of a treatment, one should try to ensure that only the treatment varies across groups. In this case, the new device is compared to an old device. However, the new device also requires that users stay well hydrated. If we observe any positive effects from the new device, we won't know whether the new device is effective, or if merely staying well hydrated is actually what is effective. To rule out this confounding variable, we should also ask the group using the old machine condition to stay hydrated as well.
← Didn't Know|Knew It →
An experiment was done by medical researchers to determine the association between drinking caffeine and severity of lung cancer. Results showed that there was a high association between the two variables. Which of the following could be a potential confounding variable in the experiment?
An experiment was done by medical researchers to determine the association between drinking caffeine and severity of lung cancer. Results showed that there was a high association between the two variables. Which of the following could be a potential confounding variable in the experiment?
Tap to reveal answer
A confounding variable is one that could potentially have an effect on both the independent and dependent variables in a study. In this case, it is possible that there is an association between smoking and caffeine as well as smoking and lung cancer.
A confounding variable is one that could potentially have an effect on both the independent and dependent variables in a study. In this case, it is possible that there is an association between smoking and caffeine as well as smoking and lung cancer.
← Didn't Know|Knew It →
A study finds that caffeine intake has a strong positive correlation with grades for college students. In other words, on average, the more caffeine intake a student has, the higher a grade the student gets.
Which of the following could potentially be a confounding variable in this experiment?
A study finds that caffeine intake has a strong positive correlation with grades for college students. In other words, on average, the more caffeine intake a student has, the higher a grade the student gets.
Which of the following could potentially be a confounding variable in this experiment?
Tap to reveal answer
The only confounding variable in this experiment is the amount of sleep that each student gets. A confounding variable is one that has an impact on both the dependent and independent variable. It is possible that the amount of sleep a student gets is related to caffeine intake, which in turn affects the grade a student receives on a test or assignment.
The only confounding variable in this experiment is the amount of sleep that each student gets. A confounding variable is one that has an impact on both the dependent and independent variable. It is possible that the amount of sleep a student gets is related to caffeine intake, which in turn affects the grade a student receives on a test or assignment.
← Didn't Know|Knew It →
An experiment testing the effects of caffeine on endurance performance in athletes assigns caffeine to a randomly selected group of athletes and has them exercise. Another trial was conducted in which the same group exercised without anything given to them to take. The results did not match the expected results. What should be done to improve this experiment?
An experiment testing the effects of caffeine on endurance performance in athletes assigns caffeine to a randomly selected group of athletes and has them exercise. Another trial was conducted in which the same group exercised without anything given to them to take. The results did not match the expected results. What should be done to improve this experiment?
Tap to reveal answer
The placebo effect can potentially be a confounding variable. By knowingly taking a substance, participants may feel more energenized. By administering the same substance both trials, with the only thing changed being caffeine content, this corrects for this possible confounding variable.
The placebo effect can potentially be a confounding variable. By knowingly taking a substance, participants may feel more energenized. By administering the same substance both trials, with the only thing changed being caffeine content, this corrects for this possible confounding variable.
← Didn't Know|Knew It →
A small local umbrella company is trying to test the effectiveness of their umbrellas by looking at how many umbrellas they sell each year.
In 2014, the company sold 2,000 umbrellas.
In 2015, they sold 1,500 umbrellas.
They assume that their umbrellas are less effective which is why sales decreased.
However, there could be many confounding factors. Which of the following is NOT a possible confounding factor?
A small local umbrella company is trying to test the effectiveness of their umbrellas by looking at how many umbrellas they sell each year.
In 2014, the company sold 2,000 umbrellas.
In 2015, they sold 1,500 umbrellas.
They assume that their umbrellas are less effective which is why sales decreased.
However, there could be many confounding factors. Which of the following is NOT a possible confounding factor?
Tap to reveal answer
Any of these answers could explain why umbrella sales dropped. You cannot assume any specific cause explains a change in data like this-- further experimentation should be done rather than assuming cause and effect.
Any of these answers could explain why umbrella sales dropped. You cannot assume any specific cause explains a change in data like this-- further experimentation should be done rather than assuming cause and effect.
← Didn't Know|Knew It →
A bird watcher observed how many birds came to her bird feeder for four days. These were the results:
Day 1: 15
Day 2: 12
Day 3: 10
Day 4: 13
Which answer is closest to the standard deviation of the number of birds to visit the bird feeder over the four days?
A bird watcher observed how many birds came to her bird feeder for four days. These were the results:
Day 1: 15
Day 2: 12
Day 3: 10
Day 4: 13
Which answer is closest to the standard deviation of the number of birds to visit the bird feeder over the four days?
Tap to reveal answer
Standard deviation is essentially the average distance from the mean of a group of numbers. There are a number of steps in computing standard deviation, but the steps are not too complicated if you take them one at a time. First, find the mean of the values. Second, subtract the mean from the first value and square the result. Do this for all remaining values. Third, add these results together. Fourth, divide this value by the number of values. Finally, find the square root of the result.
1: 
2: 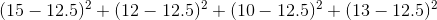
3: 
4: 
5: 
Standard deviation is essentially the average distance from the mean of a group of numbers. There are a number of steps in computing standard deviation, but the steps are not too complicated if you take them one at a time. First, find the mean of the values. Second, subtract the mean from the first value and square the result. Do this for all remaining values. Third, add these results together. Fourth, divide this value by the number of values. Finally, find the square root of the result.
1:
2:
3:
4:
5:
← Didn't Know|Knew It →
A bird watcher observed how many birds came to her bird feeder for four days. These were the results:
Day 1: 15
Day 2: 12
Day 3: 10
Day 4: 13
What is the variance of the number of birds that visited the bird feeder over the four days?
A bird watcher observed how many birds came to her bird feeder for four days. These were the results:
Day 1: 15
Day 2: 12
Day 3: 10
Day 4: 13
What is the variance of the number of birds that visited the bird feeder over the four days?
Tap to reveal answer
Variation measures the average difference between values within a group. The process is not complicated but there are four steps that can take time. First, find the mean of the values. Second, subtract the mean from the first value and square the result. Do this for all remaining values. Third, add these results together. Fourth, divide this value by the number of values in the group minus one (in this case, there are four days).
1: 
2: 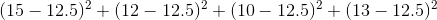
3: 
4: =4.33")
Note that to find the standard deviation, we would simply take one additional step of finding the square root of the variance.
Variation measures the average difference between values within a group. The process is not complicated but there are four steps that can take time. First, find the mean of the values. Second, subtract the mean from the first value and square the result. Do this for all remaining values. Third, add these results together. Fourth, divide this value by the number of values in the group minus one (in this case, there are four days).
1:
2:
3:
4:
Note that to find the standard deviation, we would simply take one additional step of finding the square root of the variance.
← Didn't Know|Knew It →